Сегодня хочу рассказать небольшие тонкости для качественной организации работы с R в IDE RStudio.
Я переписала свой же материал на quarto, здесь лежит старый пост.
Организация работы
Первым делом, что нужно освоить для эффективной работы - это перестать использовать setwd("C:\Users\username\path\that\only\I\have"), а также не использовать абсолютные пути для доступа к файлам.
Скажу честно, что еще совсем недавно (относительно августа) я использовала абсолютные пути и не видела в этом большого вреда, поскольку работаю преимущественно в одиночку и на одном устройстве. Однако все равно периодически приходилось переписывать пути вручную и это было неудобно. А потом я прочитала статью Дженни Брайан (Jenny Bryan) о желании сжечь компьютер злодеям, которые так делают, и теперь привыкаю следовать правильному подходу - использовать R-проекты для организации доступа к файлам.
Настоятельно рекомендую самостоятельно почитать эту статью, поскольку ниже я привожу краткую выжимку, где подчеркнула определенные вещи, а за деталями лучше обратиться к оригиналу.
Как организовать R-проекты
Еще можно почитать в книге Хэдли Викхама
Заходим в File - New Project

В зависимости от того, с нуля создается проект или вы хотите перейти на проект-ориентированный подход для существующих данных выбираем новую директорию или существующую

Например, я выбрала новую директорию,
далее выбираем New Project ->
Пишем название проекта и директорию (папку), в которой он будет располагаться. Также я ставлю галочку для открытия в новой сессии RStudio, чтобы не закрывать текущий проект. В результате открывается чистая студия, где рабочая директория будет соответствовать нужному пути. А в созданной директории появился
.RProjфайл.Теперь при закрытии окна арстудио можно будет открыть этот файл и все будет в том виде, в котором вы его оставили (с открытыми скриптами, даже несохраненными и с созданными переменными, последнее лучше нужно отключить, подробнее ниже).
Если же создавать проект в существующей директории, то это еще проще, просто выбираем нужный путь к ней и открываем проект, можно также в новой сессии.
Рекомендуется организовать данные в проекте определенным одинаковым образом для удобства работы. Например, создать отдельную директорию
dataдля данных, можно создать дополнительные папки для сырых и процессированных данных (raw,processed), а еще создать отдельную директорию для рисунков.Подробнее можно почитать в книге Ивана Позднякова, которому отдельное спасибо за дискуссии в твиттере и выявление антипаттернов!
Еще рекомендуется использовать пакет
hereдля универсального доступа к файлам вне зависимости от используемой системы (Windows/Linux/Mac) и текущей директории.
Почитать о преимуществах можно здесь и в документации к пакету.Ну и последняя по порядку, но не по значению рекомендация в этой части. Хочу поделиться замечательным руководством Дженни Брайан о правильном именовании файлов для удобной работы, это относится вообще ко всему, не только с точки зрения программирования https://speakerdeck.com/jennybc/how-to-name-files
Почему не нужно использовать rm(list = ls()) в начале каждого скрипта?
Второй антипаттерн, которым я тоже страдала совсем недавно, это привычка писать в начале скрипта rm(list = ls())для удаления всех переменных.
Мне казалось, что это классно придумано, ведь при запуске скрипта я удаляю старые переменные в одну строчку, не надо руками нажимать на метелку в окружении переменных и нет риска запутаться со старыми переменными.
Однако, с таким подходом я иногда забывала эксплицитно подгрузить часть пакетов (через library), потому что они были загружены ранее при выполнении других скриптов. В результате скрипт оказывается невоспроизводимым, особенно нехорошо, если понадобится делиться скриптом с коллегами.
Все это можно легко решить, сделав несколько настроек в RStudio: Tools -> Global Options -> General - убираем галочку с восстановления .RData при запуске студии и выбираем никогда не сохранять .RData при выходе.
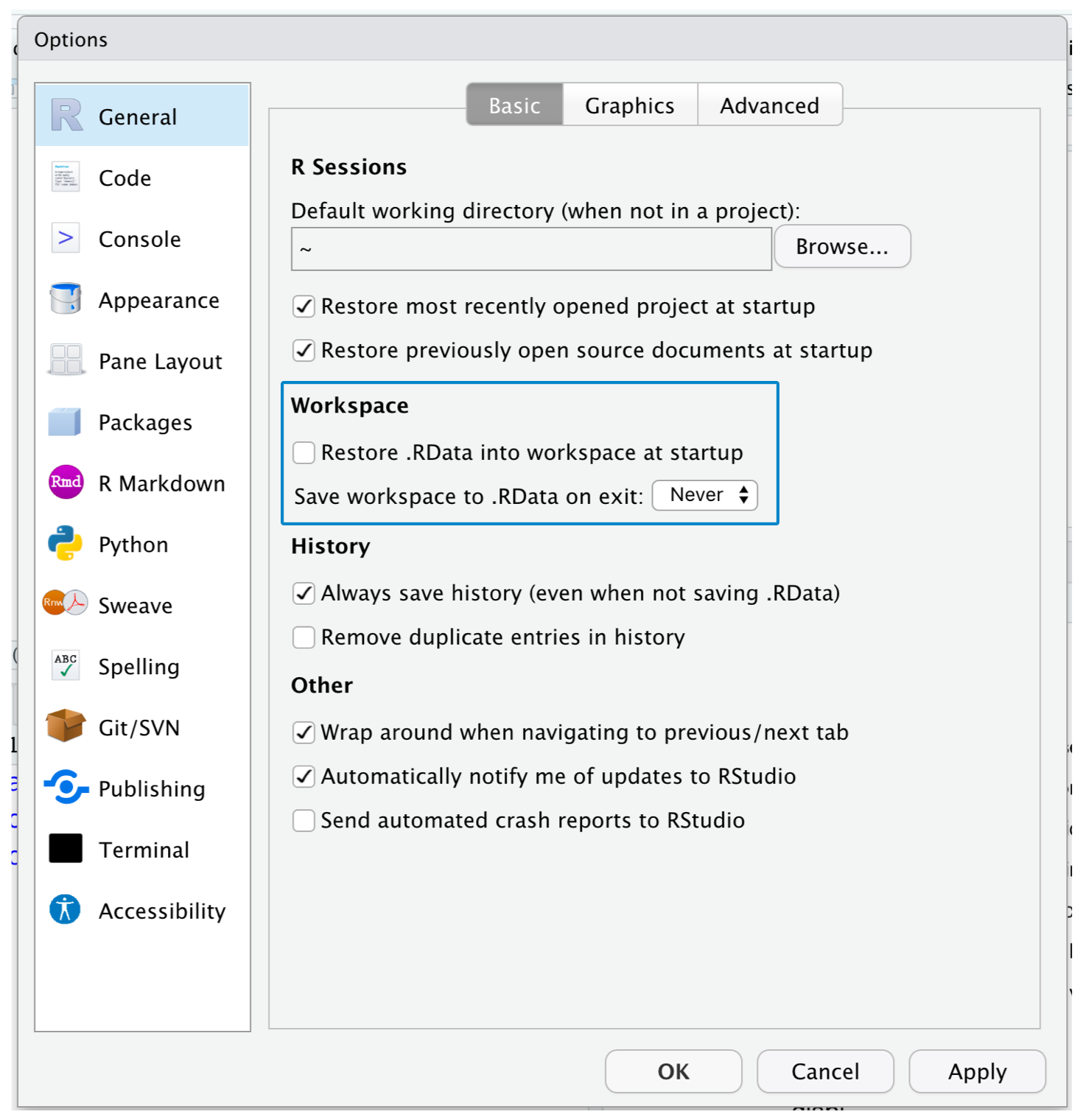
Итак, вместо того чтобы удалять переменные в начале нового скрипта, лучше воспользоваться сочетанием горячих клавиш Ctrl/Cmd+Shift+F10. Таким образом мы полностью перезапустим сессию, удалив старые переменные, а также проверим, что не забыли загрузить нужные пакеты в начале скрипта.
Кроме того, полезно перезапускать сессию таким сочетанием клавиш в процессе работы, чтобы убедиться, что все нужные переменные созданы в рамках скрипта, а не где-то когда-то были подсчитаны в консоли и висят в окружении, что опять-таки вызовет проблемы с воспроизводимостью при запуске вашего скрипта с нуля.
Стилистические рекомендации
Можно ознакомиться с полным списком рекомендаций по стилю кода в книге Хэдли Викхама, здесь приведу выдержку самых важных на мой взгляд
В R для именования переменных принят
snake_case, то есть рекомендуется использовать в качестве разделителя нижнее подчеркивание (а не например заглавные буквы -camelCaseи не точки). Но конечно жеcamelCaseне запрещен к использованию, главное правило - оставаться последовательным, то есть если решили использоватьcamelCase, то так и делать на протяжении всего проекта. Почитать детальнее можно здесь и здесь: это главы из книги Хэдли Викхама R for Data Science.Не стоит использовать сокращения
TиFотTRUEиFALSE, поскольку полные наименования R защищает от переписывания, а вот сокращения нет и можно попасть в глупую ситуацию, создав в какой-то момент переменнуюTилиF.Лучше использовать в качестве оператора присваивания
<-, а не=
Если что, стрелочку можно вставить с помощью хоткеяAlt -(альт минус) в RStudio. Правоприсвоение (2 -> a) не рекомендуется, так как снижает читаемость кода.Еще мне понравилось, что в новых версиях RStudio можно сделать скобки разноцветными, чтобы облегчить восприятие вложенного кода (хотя сильной вложенности кода стоит по возможности избегать). Чтобы это сделать, нужно зайти в Tools - Global Options - Code - Display и поставить галочку здесь:

Совет новичкам (и не только новичкам) как наиболее эффективно просить помощи с кодом у коллег.
Как минимум скидывать код и скриншот ошибки (не фото на телефон экрана!), чтобы не было просто: “АААА у меня ничего не работает”.В идеале готовить воспроизводимые примеры ошибки, например с помощью пакета
reprex. В книге Викхама Mastering Shiny можно почитать, как это работает, расписано с точки зрения отладки Shiny app, но на самом деле это работает для любых трудностей в коде.Полезные хоткеи при работе в RStudio (для пользователей Mac OS Ctrl = Cmd):
Alt + -(Альт минус) чтобы вставить оператор присваиванияCtrl/Cmd+Enterдля запуска строчки кода (можно выделять несколько строк и запускать их)Ctrl+Shift+Cдля быстрого комментирования и раскомментирования строчки кодаCtrl+Shift+Mдля вставки пайпа%>%Ctrl+Shift+Enterдля запуска скрипта целикомCtrl+Shift+F10для перезапуска арстудии. Полезно в сочетании с предыдущей командой для проверки, что все в скрипте хорошо работает.Напоминаю, что можно пользоваться табом для автодополнения названий переменных и функций.
Также напоминаю, что в консоли с помощью стрелки вверх можно вызвать предыдущие команды.
С полным списком хоткеев можно ознакомиться в Tools - Keyboard Shortcuts Help или лично мне удобнее их смотреть в Tools - Modify Keyboard Shortcuts.
Полезные материалы и ссылки
Много раз упомянутая статья Дженни Брайан, еще раз настоятельно рекомендую почитать
Книга авторов Jenny Bryan и Jim Hester. Тоже советую ознакомиться, хотя целиком я ее сама не прочитала. Здесь собраны как советы новичкам, так и советы для продвинутых юзеров, например как правильном искать ошибки в R (не только дебаг принтом)).
Презентация Дженни Брайан о правильном именовании файлов.
Организация работы с Git в R
Книга Ивана Позднякова “Анализ данных и статистика в R”. Узнала про книгу после курса Бластима, всем рекомендую + на русском языке.