Язык программирования R для анализа данных: лекция 6
Введение в статистику вывода
Что такое выборка?
Выборка — часть генеральной совокупности элементов, доступная для исследования.
![]()

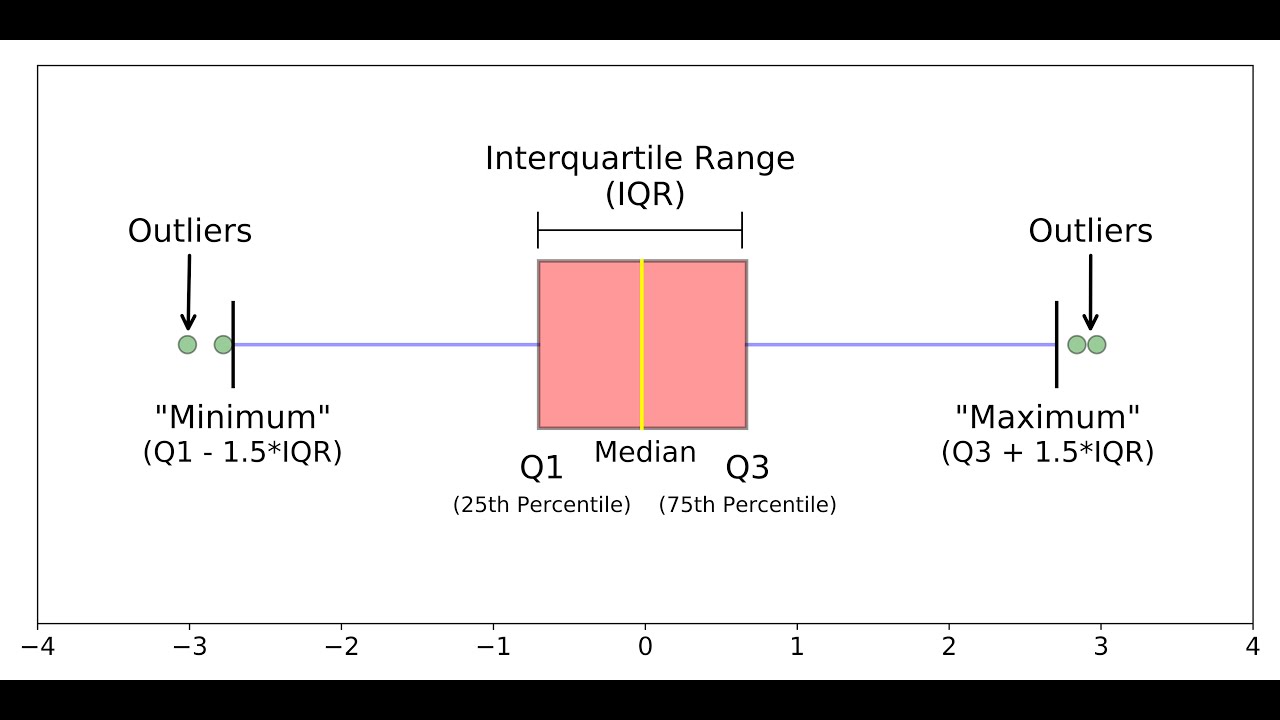
Межквартильный размах или как интерпретировать боксплот
Боксплот
Нормальное распределение
Непрерывное распределение вероятностей с пиком в центре и симметричными боковыми сторонами, которое в одномерном случае задаётся функцией плотности вероятности, совпадающей с функцией Гаусса.

Нормальное распределение

Центральная предельная теорема
Используем лог-нормальное распределение:

Как будут распределены средние из лог-нормального распределения?

Они будут распределены нормально!