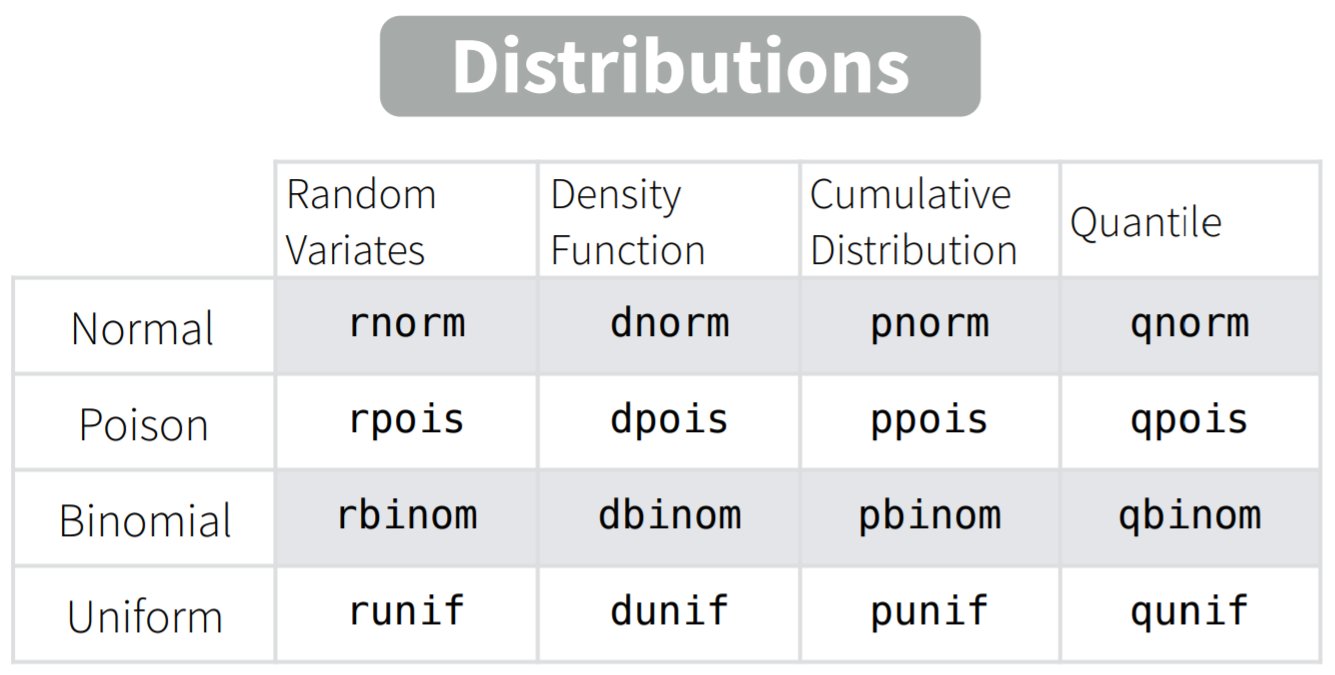
Statistics (обозначают например \(\overline{x}\), \(sd\))
Например, у стандартного нормального распределения среднее \(\mu\) 0 и стандартное отклонение \(\sigma\) 1, и эти значения являются параметрами, поскольку описывают теоретическое распределение (генеральную совокупность).
Например, в датасете iris среднее Sepal.Length равно 5.84, а стандартное отклонение 0.828, и эти значения являются статистиками (описывают выборку).
mean(iris$Sepal.Length)
[1] 5.843333
sd(iris$Sepal.Length)
[1] 0.8280661
Полезные функции для генерации различных распределений
Можно посмотреть в cheatsheet по base R.
Наиболее полезные функции: density (d*()), cumulative distribution (p*()) и random (r*()).
Со списком всех доступных в base R распределений можно ознакомиться, вызвав
?Distributions
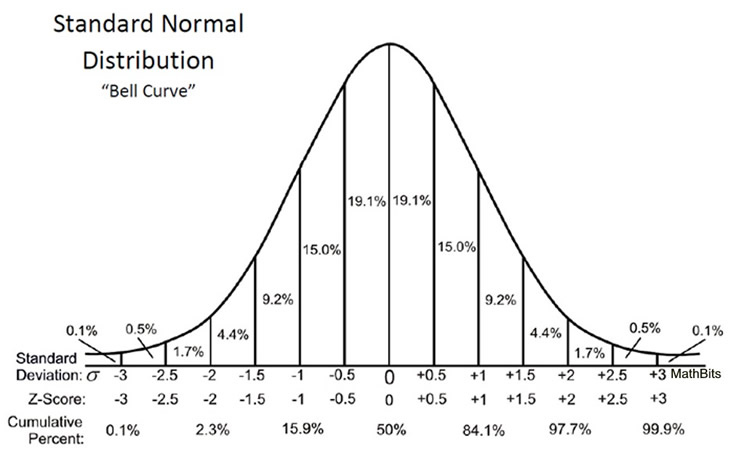
Стандартное нормальное распределение
Стандартное нормальное распределение имеет среднее 0 и стандартное отклонение 1. Важно отметить, что здесь мы говорим о параметрах генеральной совокупности, а не о статистиках.
Функция плотности вероятности нормального распределения: dnorm()
Density function
dnorm(0)
[1] 0.3989423
# что получится, если запустить dnorm(1)?
dnorm(1)
[1] 0.2419707
# а если запустить dnorm(-1)?
dnorm(-1)
[1] 0.2419707
Функция плотности вероятности стандартного нормального распределения
Забавный момент: для дискретных распределений называется probability mass function, для непрерывных - probability density function, на русский язык переводится одинаково: функция плотности вероятности.
Давайте отрисуем функцию плотности вероятности стандартного нормального распределения с помощью dnorm().
vec <-seq(-3, 3, 0.01)plot(vec, dnorm(vec))
Функция плотности вероятности шкалы IQ
iq <-seq(50, 150, 0.1)plot(iq, dnorm(iq, mean =100, sd =15))
Шкала IQ отнормирована таким образом, чтобы среднее генеральной совокупности было равно 100, а стандартное отклонение 15.
pnorm() - кумулятивная функция распределения (cumulative density function)
На примере стандартного нормального распределения.
plot(vec, pnorm(vec))
pnorm() отражает вероятность получить такое же или меньшее значение в нормальном распределении (в данном случае в стандартном).
pnorm() - кумулятивная функция распределения (cumulative density function)
На примере шкалы IQ.
Чему будет равно значение pnorm(100) для этой шкалы? То есть какая вероятность получить значение меньше чем 100?
pnorm(100, mean =100, sd =15) # не забываем прописывать mean, sd
[1] 0.5
Среднее равно 100, следовательно -> пояснение на графике
Чему равно значение pnorm(130) для шкалы IQ?
pnorm(130, mean =100, sd =15)
[1] 0.9772499
rnorm() - функция для генерации случайных значений из заданного распределения
set.seed(42) # для воспроизводимости 'рандома'rnorm(30)
Сид нужно фиксировать каждый раз перед запуском чего-то зависящего от случайности.
Вычисление стандартного отклонения
set.seed(50) # для фиксации рандомаsamp <-rnorm(100, mean =100, sd =15)sqrt(sum((samp -mean(samp)) ^2) / (length(samp))) # совпадает ли с результатом функции sd?
Такая оценка стандартного отклонения называется несмещенной (unbiased) оценкой.
Почему n-1 в знаменателе -> объяснение на графике.
Значение центральной предельной теоремы
Мысленный эксперимент: многократно извлекаем выборки из генеральной совокупности, считаем средние по выборкам.
samp_means <-replicate(1000, mean(rnorm(100, mean =100, sd =15)))hist(samp_means, breaks =30)
Распределение средних, извлеченных из нормального распределения, примерно нормальное. Это неудивительно, попробуем теперь в качестве генеральной совокупности использовать лог-нормальное распределение.
Лог-нормальное распределение
hist(rlnorm(100), breaks =30)
Распределение средних лог-нормального распределения
А вот распределение средних из изначально не-нормального распределение тоже похоже на нормальное распределение! Это получается благодаря центральной предельной теореме.
Стандартное отклонение выборочного распределения средних называется еще стандартной ошибкой или standard error of the mean (s.e.m.). Нередко стандартную ошибку используют на графиках в качестве error bars.
sem <-15/sqrt(length(samp))sem
[1] 1.5
Поскольку обычно мы не знаем истинное стандартное отклонение генеральной совокупности (\(\sigma\)), то используем стандартное отклонение выборки \(sd\).
\[
s_{\overline{x}}= \frac{sd} {\sqrt{n}}
\]
Доверительный интервал
Мы хотим поймать симметрично 95% от площади под кривой. Для этого нам нужно отбросить по 2.5% с обоих сторон. Эти 2.5% соответствуют примерно двум стандартным отклонениям от среднего. Если быть точнее, то 1.96. Если быть еще точнее:
qnorm(0.975)
[1] 1.959964
zcr <-qnorm(1- (1-0.95)/2)zcr
[1] 1.959964
sem <-15/sqrt(length(samp))mean(samp) - sem*zcr #нижняя граница
Подсчет p-value как площади под кривой выборочного распределения тестовых статистик.
Вывод: отклоняем или не отклоняем нулевую гипотезу.
Разберем на примере z-теста
Формулировка нулевой и альтернативной гипотезы:
\(H_0\): \(m = \mu\) нулевая гипотеза, например, что среднее выборки статистически не отличается от среднего генеральной совокупности
\(H_1: m \neq \mu\) альтернативная гипотеза, о том что средние не равны
Вычисление тестовой статистики
Формула z-скора
\[
z = \frac{m - \mu_{H_0}}{\sigma/\sqrt{N}},
\]
где m - среднее выборки, \(\mu_{H_0}\) - среднее генеральной совокупности, \(\sigma\) - стандартное отклонение генеральной совокупности, \(N\) - размер выборки.
set.seed(42) # для фиксации рандомаsamp <-rnorm(100, mean =100, sd =15)m <-mean(samp)m
[1] 100.4877
sem <-15/sqrt(length(samp))z <- (m -100)/semz
[1] 0.3251482
Вычисление p-value
pnorm(z)
[1] 0.6274655
pnorm() считает от минус бесконечности до заданного числа, а нам нужно наоборот — от заданного числа до плюс бесконечности, потому что \(z\) больше нуля. Этого можно добиться вычитанием из 1.
Поскольку мы не знаем в какую сторону у нас ожидается эффект, то нужно еще учесть симметричную площадь под кривой.
1-pnorm(z)
[1] 0.3725345
p_value <- (1-pnorm(z))*2p_value
[1] 0.7450689
Много это или мало? Какой делаем вывод?
Вывод
p-value > 0.05, порогового значения \(\alpha\), следовательно мы НЕ отклоняем нулевую гипотезу.
Тест Стьюдента или t-test
На практике z-тест не используется, потому что предполагает, что мы знаем стандартное отклонение в генеральной совокупности. Обычно это не так, поэтому мы оцениваем стандартное отклонение в генеральной совокупности на основе стандартного отклонения по выборке.
Это приводит к тому, что тестовая статистика уже не распределена нормально, а распределена согласно t-распределению. Статистика называется t-статистикой.
\[
t = \frac{\overline{x} - \mu} {s_x / \sqrt{N}}
\]
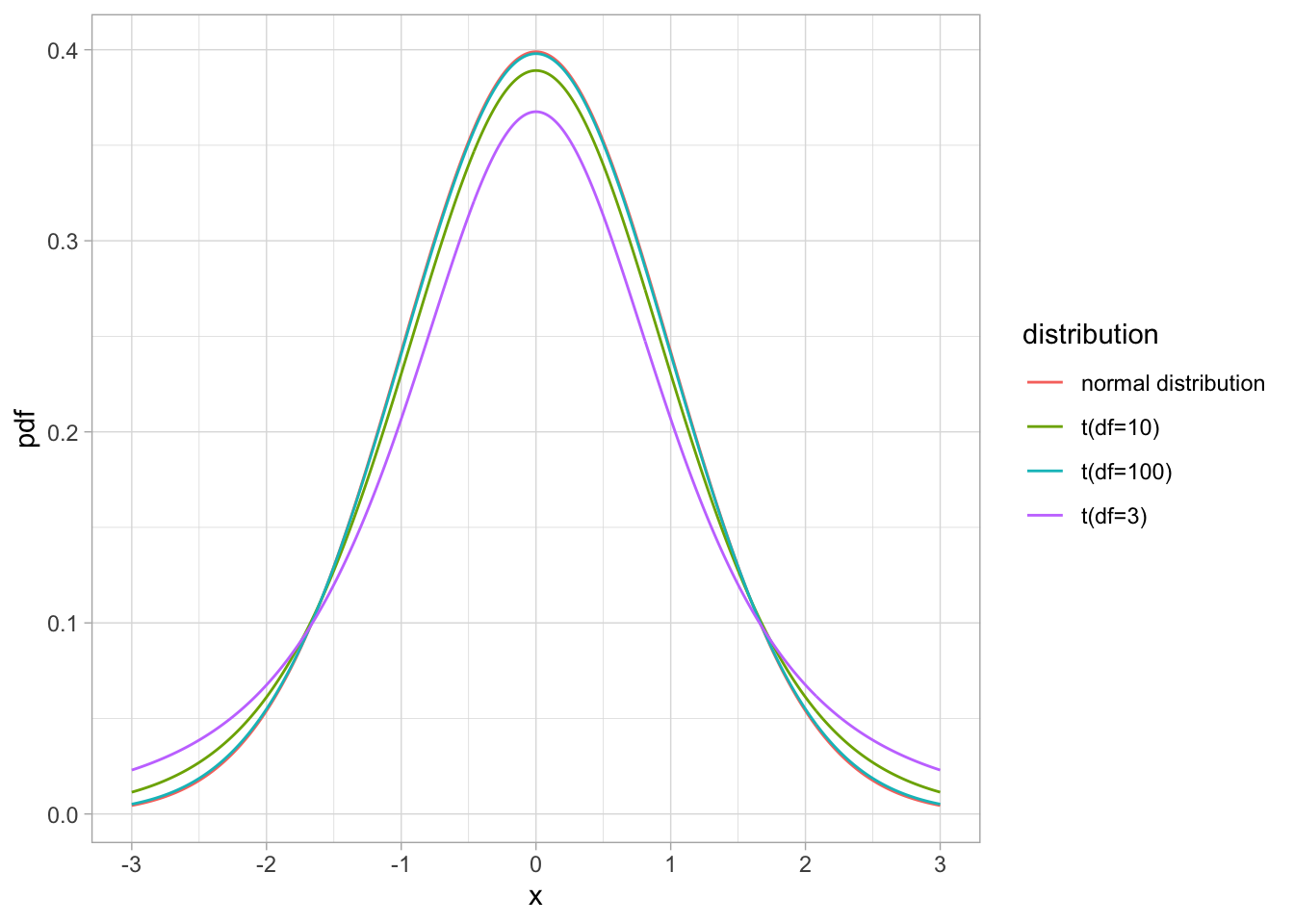
Распределение Стьюдента или t-распределение
Есть параметр степеней свободы: размер выборки -1
t-распределение имеет более тяжелые хвосты.
При размере выборке стремящемуся к бесконечности, t-распределение стремится к нормальному.
Проведение теста Стьюдента
Формулировка нулевой и альтернативной гипотезы не изменилась.
Теперь в качестве тестовой статистики вычисляем t-статистику по формуле:
\[
t = \frac{\overline{x} - \mu} {s_x / \sqrt{N}}
\]
m <-mean(samp)sem <-sd(samp)/sqrt(length(samp)) # разница на этом шагеt <- (m -100)/semt
[1] 0.3122351
(m -100) / (15/sqrt(100)) # это z-score, значения близки
[1] 0.3251482
Вычисление p-value в тесте Стьюдента
Теперь вычисляем p-value как площадь под кривой распределения t-статистики. Для этого используем уже не pnorm(), а pt().
pt(t, df =length(samp) -1) # здесь различие от z-теста
[1] 0.6222407
1-pt(t, df =length(samp) -1) # односторонний
[1] 0.3777593
(1-pt(t, df =length(samp) -1))*2# двусторонний
[1] 0.7555186
t.test(samp, mu =100) # проверка
One Sample t-test
data: samp
t = 0.31224, df = 99, p-value = 0.7555
alternative hypothesis: true mean is not equal to 100
95 percent confidence interval:
97.38831 103.58714
sample estimates:
mean of x
100.4877
Картинка Ивана Позднякова с описанием этапов статистического вывода
Welch Two Sample t-test
data: wc3_units_armor$hp by wc3_units_armor$armor_type
t = -2.3602, df = 21.493, p-value = 0.02778
alternative hypothesis: true difference in means between group Heavy and group Light is not equal to 0
95 percent confidence interval:
-536.65167 -34.28877
sample estimates:
mean in group Heavy mean in group Light
533.6207 819.0909
Можно в функцию t.test() подавать два вектора:
t.test(seq(1, 10, 0.1), seq(5, 12, 0.2))
Welch Two Sample t-test
data: seq(1, 10, 0.1) and seq(5, 12, 0.2)
t = -6.7082, df = 80.014, p-value = 2.564e-09
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-3.889981 -2.110019
sample estimates:
mean of x mean of y
5.5 8.5
Тест Стьюдента и тест Велча
На самом деле по умолчанию в R запускается тест Велча, поскольку предполагается, что дисперсии двух выборок не равны
Two Sample t-test
data: wc3_units_armor$hp by wc3_units_armor$armor_type
t = -2.1765, df = 38, p-value = 0.0358
alternative hypothesis: true difference in means between group Heavy and group Light is not equal to 0
95 percent confidence interval:
-550.98551 -19.95493
sample estimates:
mean in group Heavy mean in group Light
533.6207 819.0909
Однако это делать не рекомендуется, поскольку при равных дисперсиях тест Стьюдента не будет сильно отличаться от теста Велча, а при разных тест Велча точнее.
Формула теста Велча:
\[
t = \frac{\overline{X}_1 - \overline{X}_2}{\sqrt{\frac{s_1^2}{n_1} + \frac{s_2^2}{n_2}}}
\]