Разберем недостатки схем по выбору статистических тестов, формулу теста Велча и сравним с помощью симуляций тест Стьюдента и тест Велча в разных условиях.
Проблема дорожных карт по статистике
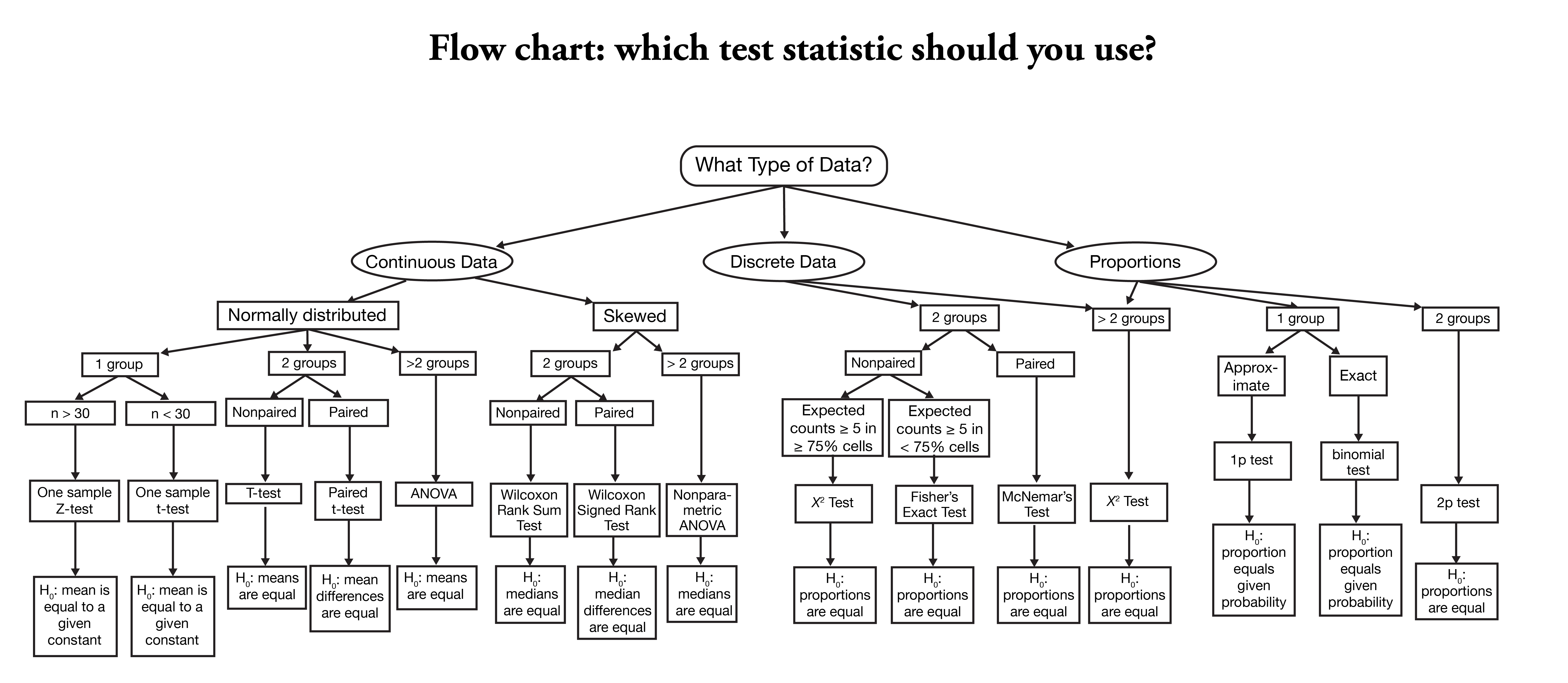
Наверняка каждый при проведении статистических тестов сталкивался с проблемой выбора подходящего теста. В научном сообществе есть определенная популярность у “дорожных карт” по выбору статистического метода, пример ниже:
Можно кликнуть на картинку и перейти на изображение в лучшем качестве
Я выбрала первую попавшуюся схему по запросу how to choose statistical test flow chart, в этой схеме есть сразу несколько ошибок, например миф про 30 наблюдений (тут вообще странное, по мнению автора схемы, при размере выборки больше 30 наблюдений можно использовать z-test).
Обычно этот миф звучит так: для небольших выборок меньше 30 наблюдений для применения t-теста нужно, чтобы было нормальное распределение данных, а если наблюдений больше 30, то можно использовать t-тест и так, в силу центральной предельной теоремы. Почему это миф, написано в статье “История одного обмана или требования к распределению в t-тесте”.
Статья подвергалась определенной критике профильных статистиков, но ключевой момент отражен верно — для t-теста не нужно нормальное распределение данных, нужно нормальное распределение тестовой статистики — то есть выборочных средних. Про это подробно собирается написать статистик Матвей Славенко, я обязательно сделаю репост, когда статья выйдет, так как для сообщества очень нужен такой материал.
Но вернемся к тесту.
Тест Велча: теория
Часто для двухвыборочного независимого теста Стьюдента можно встретить требование к равенству дисперсий, и это правильное требование, если использовать классический тест Стьюдента. Однако в большинстве статистических пакетов, в том числе в R, реализован тест Стьюдента с поправкой Велча (Welch) или просто тест Велча, или тест Стьюдента для неравных дисперсий (t-test for unequal variances), для которого нет требования по соблюдению равенства дисперсий.
И многие авторы рекомендуют использовать именно его, вне зависимости от равенства дисперсий. Давайте разберемся, так ли это.
WarningПримечание
Здесь и далее формулировка “тест Стьюдента” будет означать двухвыборочный независимый тест Стьюдента без поправки Велча.
Чтобы запустить именно тест Стьюдента в R, можно использовать аргумент var.equal = TRUE.
t.test(rnorm(100, mean =0, sd =1), rnorm(100, mean =0, sd =1), var.equal =TRUE)
Two Sample t-test
data: rnorm(100, mean = 0, sd = 1) and rnorm(100, mean = 0, sd = 1)
t = -1.2245, df = 198, p-value = 0.2222
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-0.4526324 0.1058505
sample estimates:
mean of x mean of y
-0.04823391 0.12515703
Однако это делать не рекомендуется, поскольку при равных дисперсиях тест Стьюдента не будет сильно отличаться от теста Велча, а при разных тест Велча точнее.
Формула теста Велча:
\[
t = \frac{\overline{X}_1 - \overline{X}_2}{\sqrt{\frac{s_1^2}{n_1} + \frac{s_2^2}{n_2}}}
\]
Для обучения мне проще начать рассказ с теста Стьюдента без поправки Велча, потому что на нем удобно посчитать вручную тестовую статистику и степени свободы. Однако потом обязательно уточняю, что рекомендуется использовать тест Велча, преимущество которого в необязательности требования равенства дисперсий.
NoteОффтоп
При этом в источниках о тесте Стьюдента очень часто можно встретить требование к равенству дисперсий, как и к нормальности распределения исходных данных.
Но наиболее критичным требованием для проведения теста Стьюдента является независимость наблюдений.
Давайте разберем с помощью симуляций, как работает тест Велча и тест Стьюдента в разных ситуациях.
library(tidyverse) # загрузим тайдиверс
Разберем разные кейсы: проверим и ошибку первого рода, и мощность теста при равных и разных дисперсиях, и в зависимости от равенства объемов выборок.
Отличий нет, проверка на ошибку первого рода
Одинаковое среднее и дисперсия, равный размер выборок
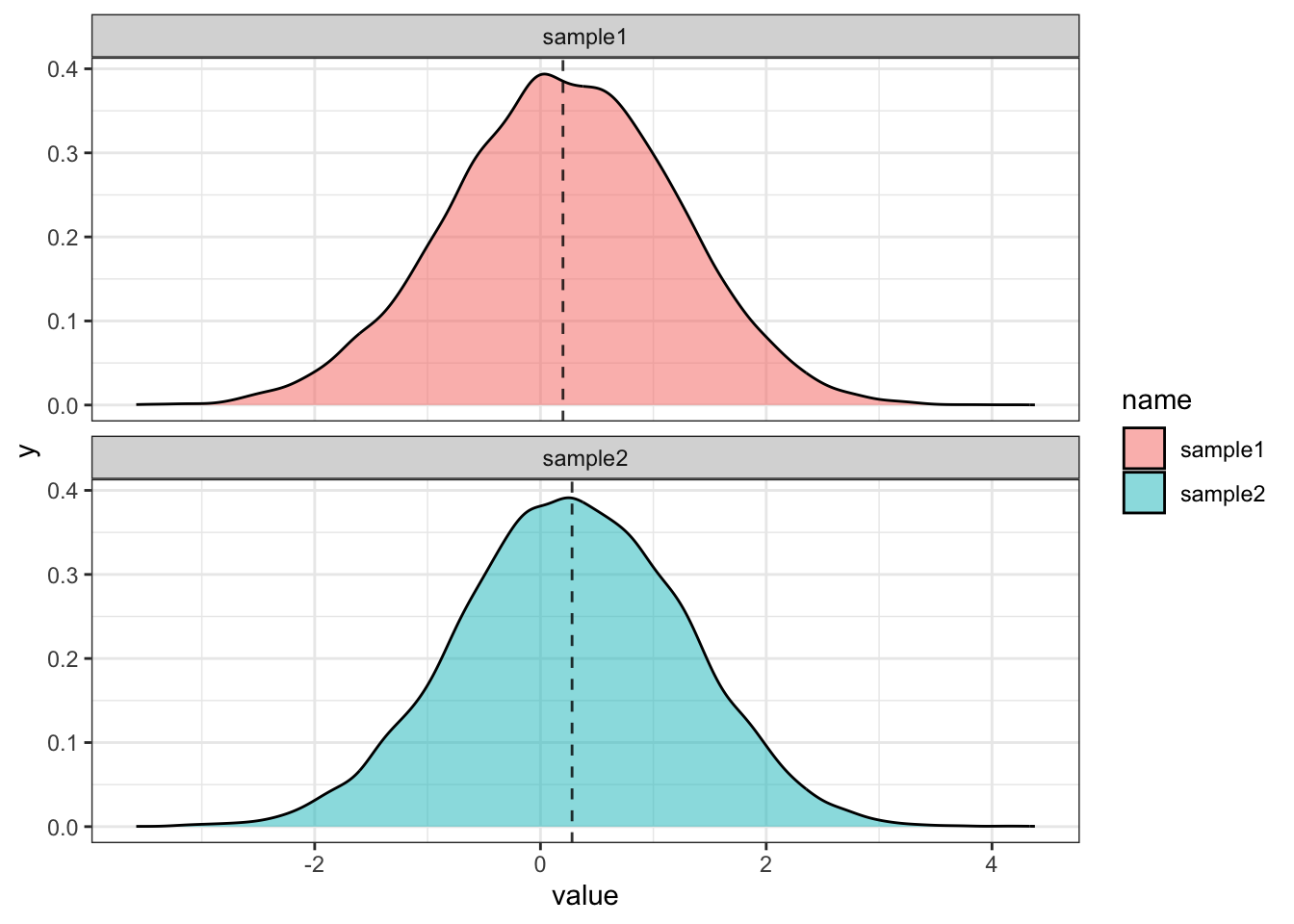
Начнем с ситуации, когда у нас обе выборки из генеральных совокупностей с одинаковым средним и дисперсией, например, здесь это нормальное распределение со средним 0.2 и стандартным отклонением 1.
TipПримечание
Здесь и в дальнейшем для симуляций будет создаваться генеральная совокупность (размером 100000) с заданными параметрами среднего и стандартного отклонения, а далее будут многократно извлекаться “выборки” заданного размера. Таким образом будет соблюдаться общая логика статистического вывода — наличие генеральной совокупности с заданными параметрами и извлечение выборок.
Для всех тестов в приведенных ниже расчетах зафиксировали уровень значимости \(\alpha=0.05\).
Тест Велча
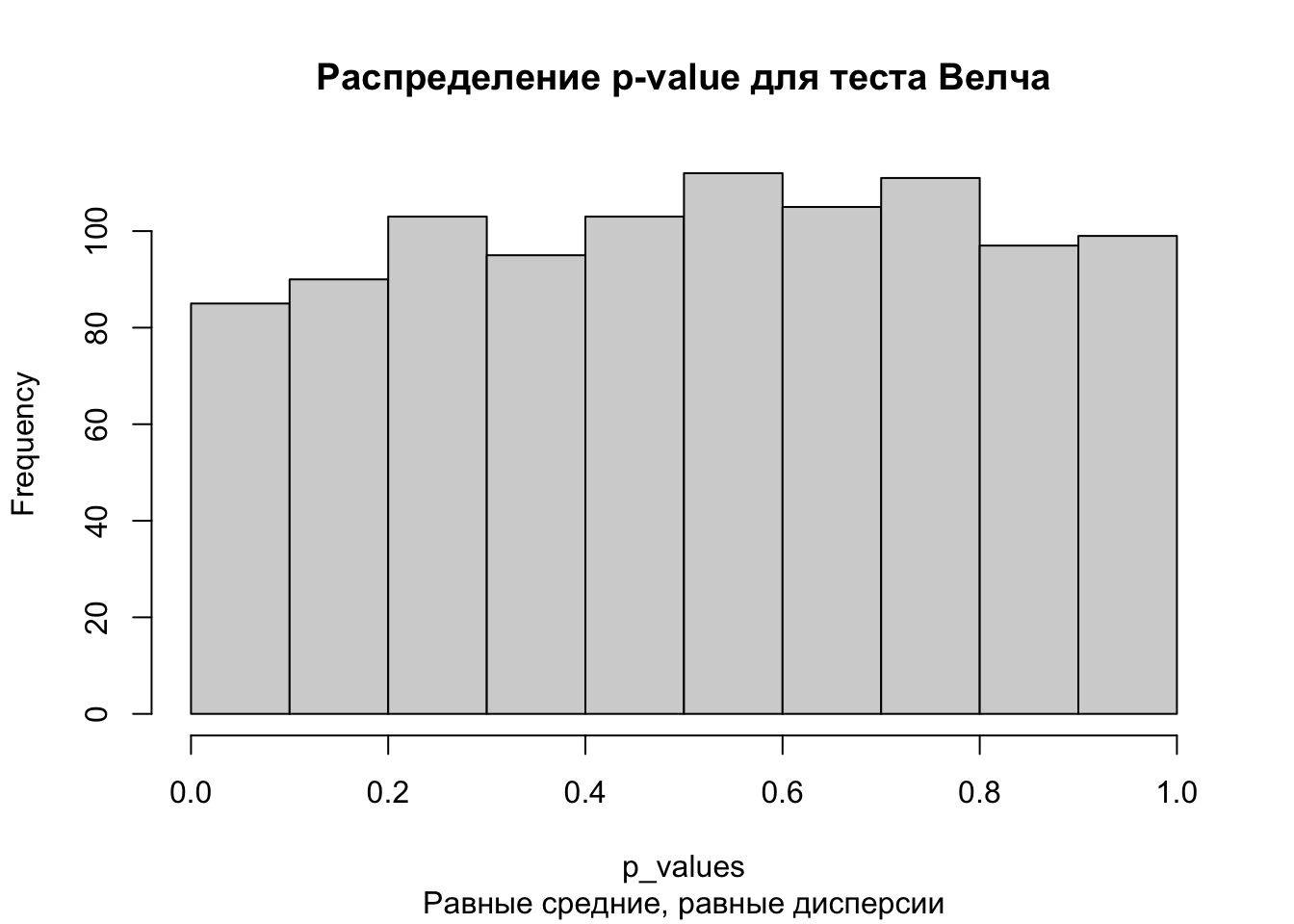
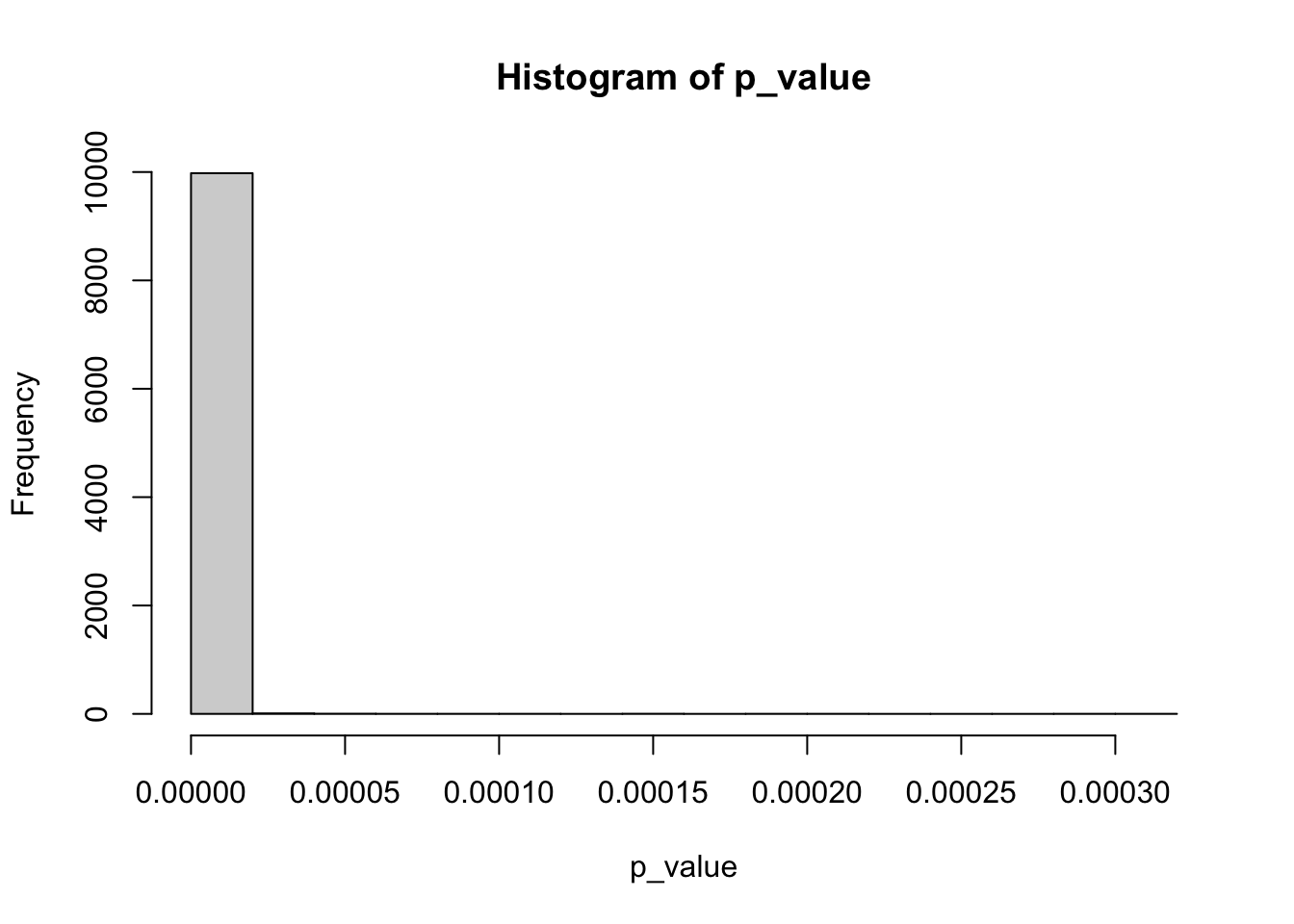
population <-rnorm(100000, mean =0.2, sd =1) # создание генеральной совокупностиp_values <-replicate(1000, t.test(population %>%sample(size =10000, replace =FALSE), population %>%sample(size =10000, replace =FALSE))$p.value)hist(p_values, main ='Распределение p-value для теста Велча',sub ='Равные средние, равные дисперсии')
mean(p_values <0.05) # доля p-value, которые оказались меньше 0.05 (прокрасились)
[1] 0.051
Тест Стьюдента
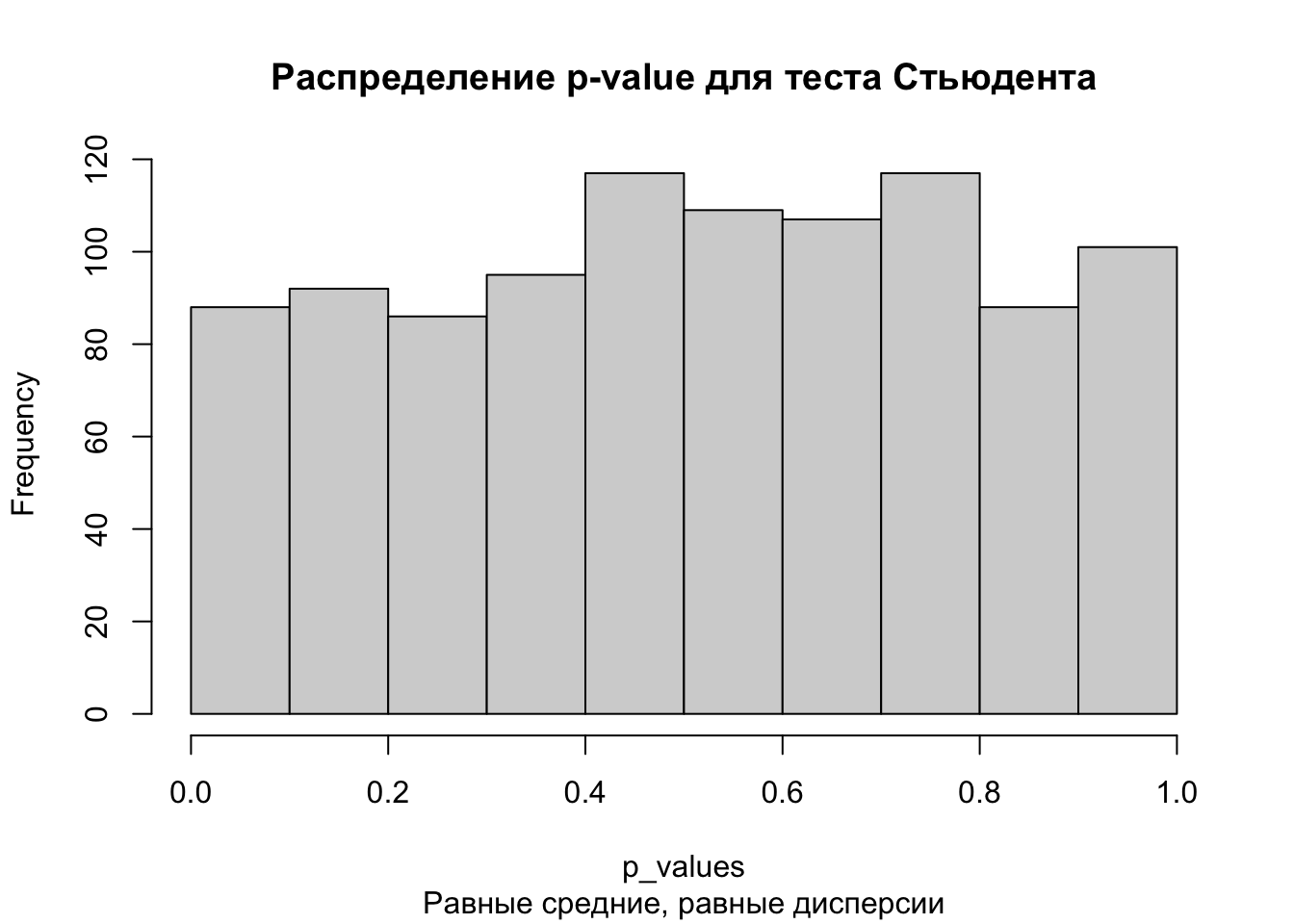
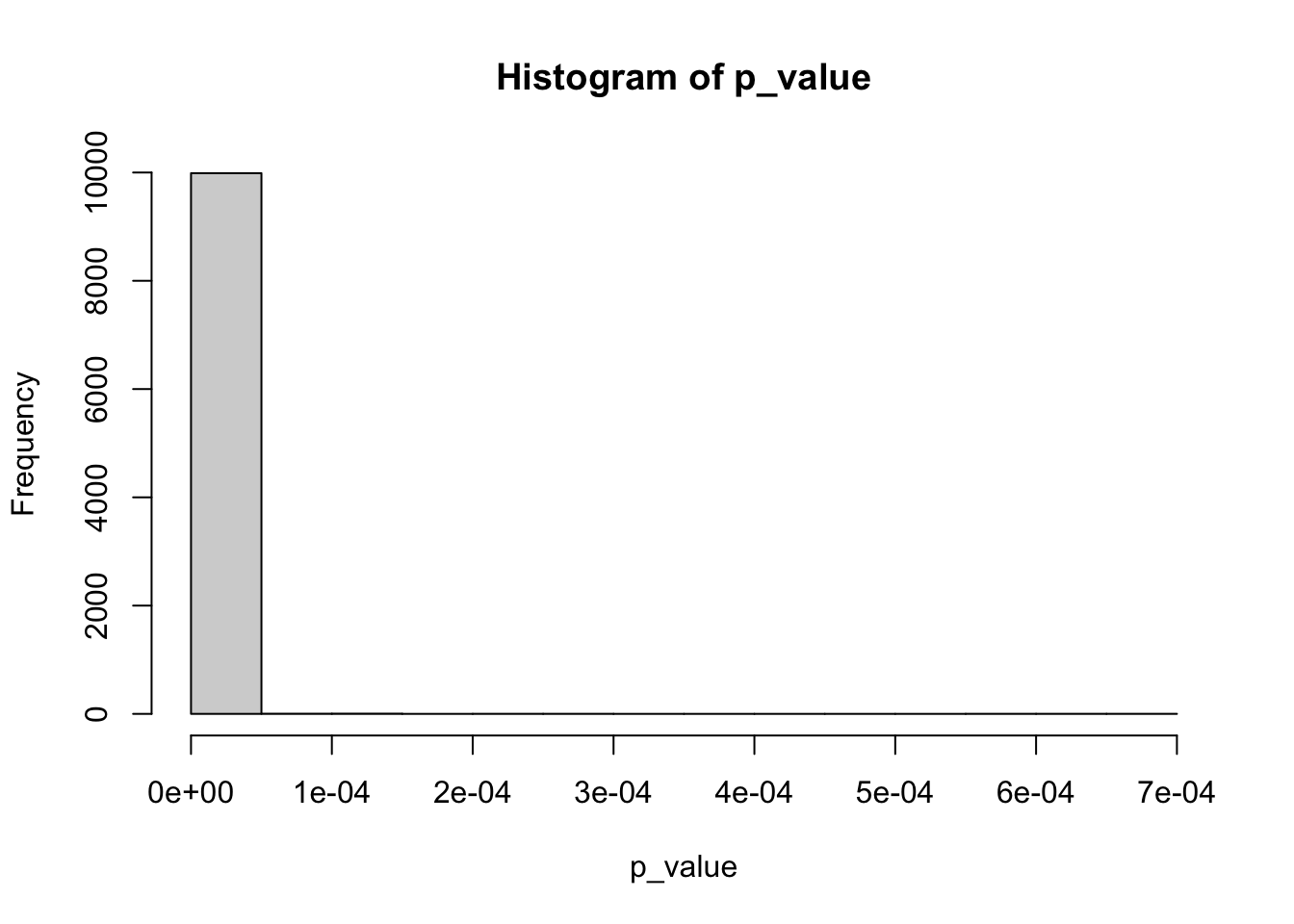
p_values <-replicate(1000, t.test(population %>%sample(size =10000, replace =FALSE), population %>%sample(size =10000, replace =FALSE), var.equal =TRUE)$p.value)hist(p_values, main ='Распределение p-value для теста Стьюдента',sub ='Равные средние, равные дисперсии')
mean(p_values <0.05) # доля p-value, которые оказались меньше 0.05 (прокрасились)
[1] 0.049
Здесь у нас вероятность ошибки первого рода для обоих тестов примерно 0.05, а также распределение p-value похоже на равномерное. Это ожидаемо и корректно, так как выборки извлекались из одинаковой генеральной совокупности, а значит, что доля ложноположительных результатов (=прокрасов) должна быть не больше заданного уровня \(\alpha = 0.05\).
Одинаковое среднее, разная дисперсия, равный размер выборок
Теперь рассмотрим случай с неравными дисперсиями. Для этого создадим две генеральные совокупности с одинаковым средним, но в одной стандартное отклонение 1, в другой 2. Извлекаем две выборки размером 10000 значений и сравниваем их тестом Стьюдента и тестом Велча.
Тест Велча
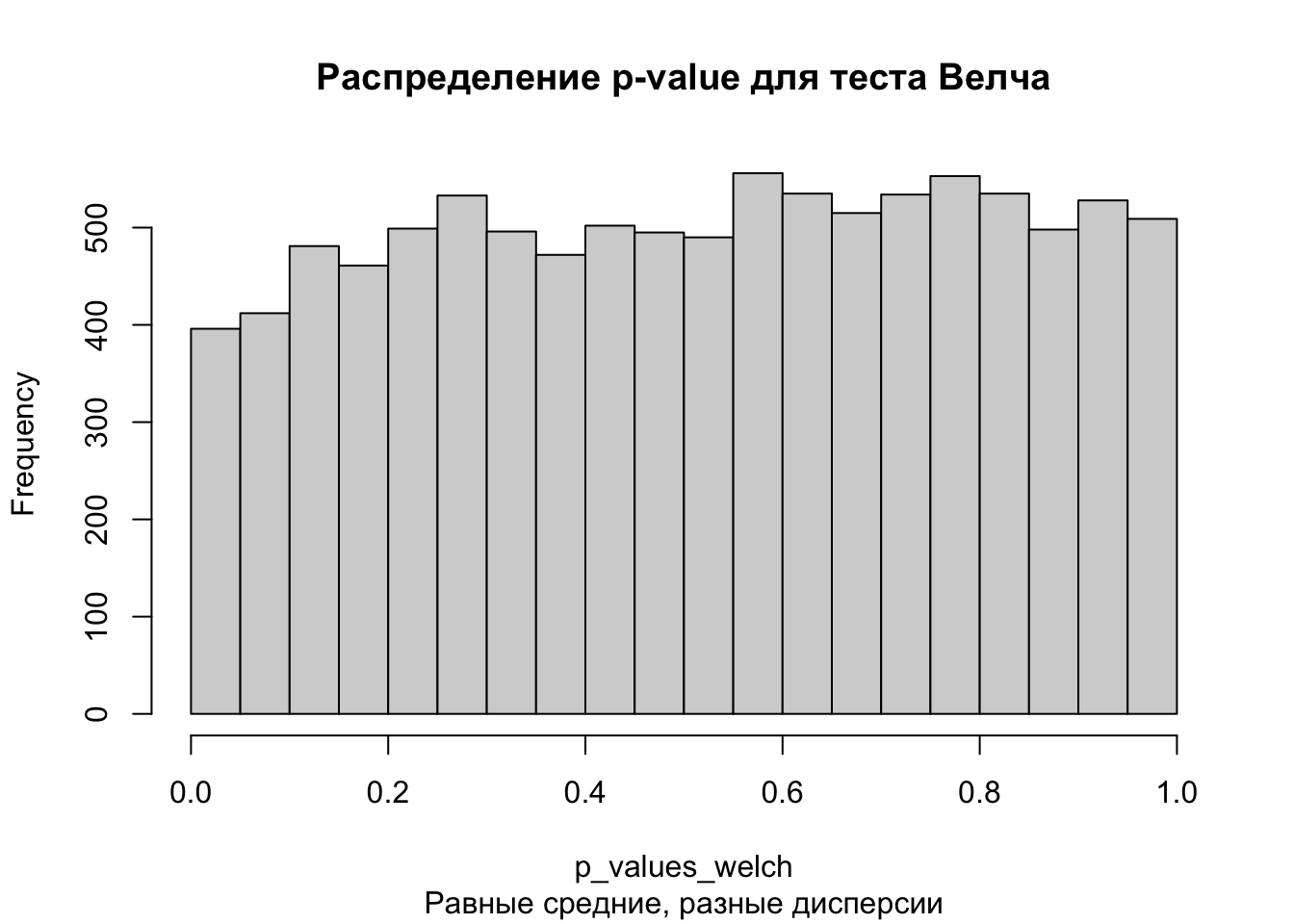
population1 <-rnorm(100000, mean =0.2, sd =1) # создание первой генеральной совокупностиpopulation2 <-rnorm(100000, mean =0.2, sd =2) # создание второй генеральной совокупности# проведение тестаp_values_welch <-replicate(10000, t.test(population1 %>%sample(size =10000, replace =FALSE), population2 %>%sample(size =10000, replace =FALSE))$p.value)hist(p_values_welch, main ='Распределение p-value для теста Велча',sub ='Равные средние, разные дисперсии')
mean(p_values_welch <0.05)
[1] 0.0396
Тест Стьюдента
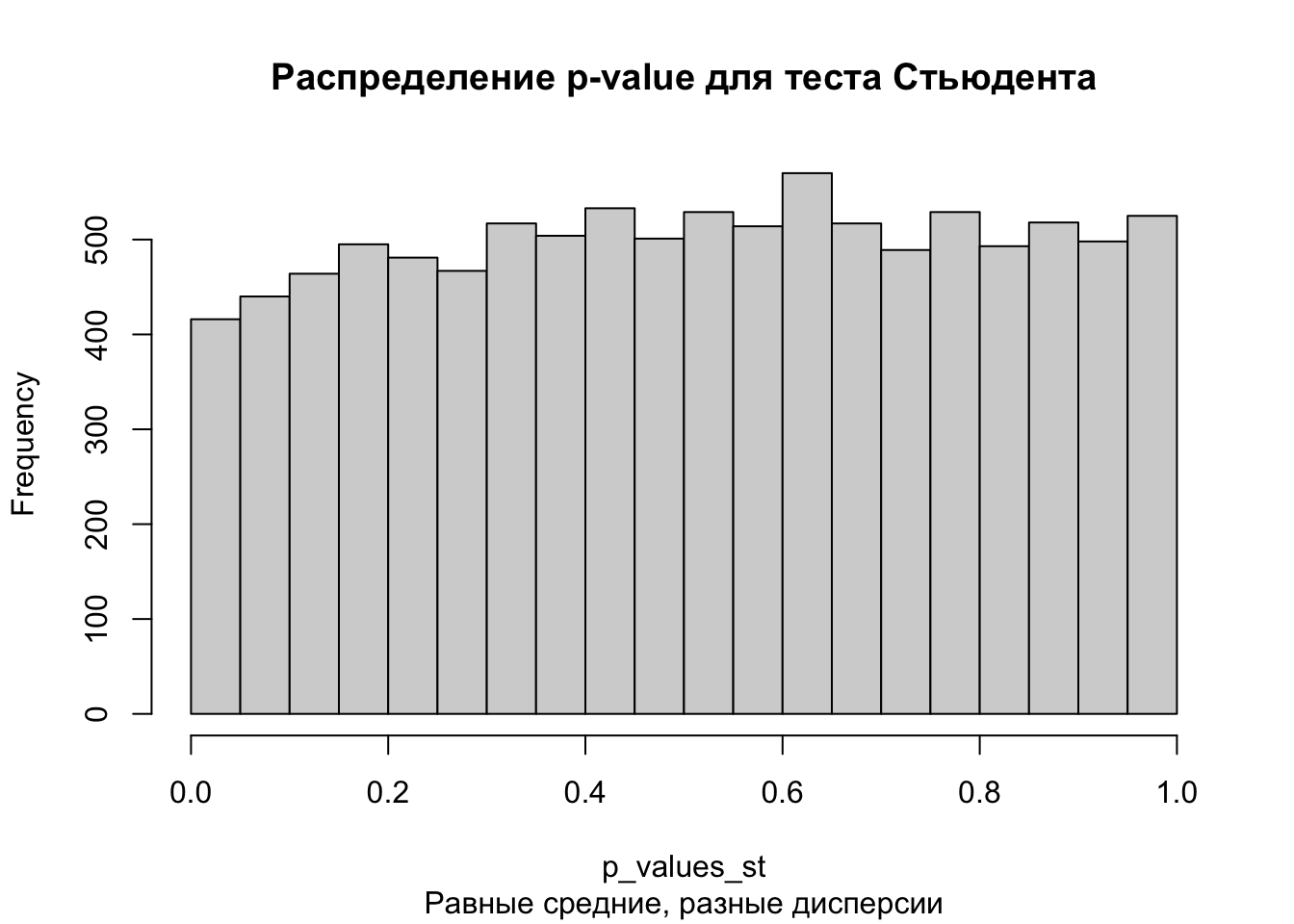
# проведение тестаp_values_st <-replicate(10000, t.test(population1 %>%sample(size =10000, replace =FALSE), population2 %>%sample(size =10000, replace =FALSE), var.equal =TRUE)$p.value)hist(p_values_st, main ='Распределение p-value для теста Стьюдента',sub ='Равные средние, разные дисперсии')
mean(p_values_st <0.05)
[1] 0.0416
Здесь выводы те же самые, как в предыдущем случае. Хоть и дисперсия в генеральных совокупностях разная, оба теста сохраняют долю ошибки первого рода на нужном уровне (меньше 0.05).
Тут важно указать, что размер выборок в данном примере одинаковый. Однако тест Стьюдента без поправки Велча становится неустойчивым с точки зрения ошибки первого рода, в случае, когда у нас выборки сильно отличаются по размеру.
Одинаковое среднее, разная дисперсия, разный размер выборок
Например, в выборке с большей дисперсией 3000 наблюдений, в выборке с меньшей дисперсией 7000 наблюдений.
WarningПримечание
Здесь я написала так для краткости, имелось ввиду: выборки, извлеченные из генеральной совокупности с большей дисперсией, содержат 3000 наблюдений, а выборки, извлеченные из генеральной совокупности с меньшей дисперсией, содержат 7000 наблюдений.
TipПример
Такая ситуация может встретиться в A/B тестировании, когда для 30% пользователей мы показываем тестовую версию, а контрольную версию видят 70% пользователей.
Получилось, что тест Стьюдента в ситуации с неравными дисперсиями и разным размером выборки показал себя хуже и мы наблюдали ложные прокрасы в 12% случаев (вместо 5%, как должно было бы быть).
С увеличением дисбаланса в размере выборок, ситуация становится хуже, например, вот что произойдет, если выборки отличаются по размеру в 9 раз (тоже может встретиться в A/B тестировании, пример, что это часто используемая практика по ссылке).
Тут для теста Стьюдента без поправки Велча получилось 24% ложноположительных результатов! Это очень много относительно заданного уровня \(\alpha=0.05\). Получается, что мы будем находить значимые отличия почти в четверти случаев, и принимать неверные решения. Тест Велча при этом сохраняет долю ложноположительных результатов на уровне 5%, как и должно быть.
Для выборок разного размера при увеличении неравенства дисперсий наблюдается дальнейшее ухудшение работы теста Стьюдента (в ситуации, когда меньшая выборка с большей дисперсией).
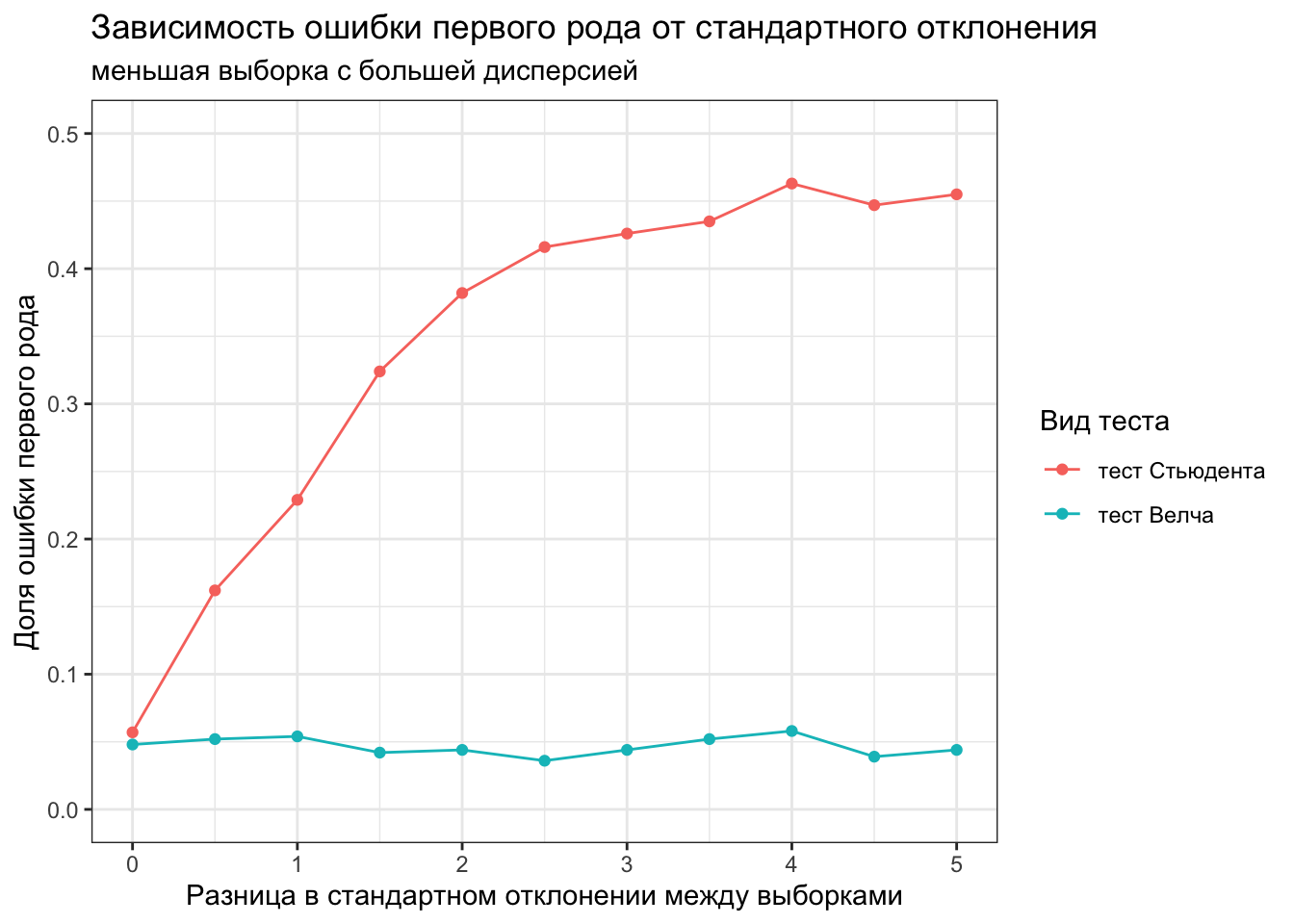
Давайте построим график зависимости ошибки первого рода от неравенства дисперсий в выборке, где размер выборок отличается в 9 раз, при этом меньшая выборка с большей дисперсией.
Code
var_size <-seq(0, 5, 0.5)calculate_mean_error_1st_type <-function(x, var.equal) {mean(replicate(1000, t.test(rnorm(9000, 0.2, 1), rnorm(1000, 0.2, 1+x), var.equal = var.equal)$p.value) <0.05)}welch_error_1st_type <-map_dbl(var_size, ~calculate_mean_error_1st_type(., FALSE))students_error_1st_type <-map_dbl(var_size, ~calculate_mean_error_1st_type(., TRUE))data.frame(var_size, welch_error_1st_type, students_error_1st_type) %>%pivot_longer(cols =c(welch_error_1st_type, students_error_1st_type), names_to ='type', values_to ='error_1st_type') %>%ggplot(aes(var_size, error_1st_type))+geom_point(aes(color = type))+geom_line(aes(color = type))+scale_x_continuous(name ='Разница в стандартном отклонении между выборками')+scale_color_discrete(name ='Вид теста', labels =c('тест Стьюдента', 'тест Велча'))+scale_y_continuous(name ='Доля ошибки первого рода', limits =c(0, 0.5))+ggtitle('Зависимость ошибки первого рода от стандартного отклонения', subtitle ='меньшая выборка с большей дисперсией')+theme_bw()
При таком дисбалансе выборок, чем больше разница в дисперсии, тем хуже работает тест Стьюдента.
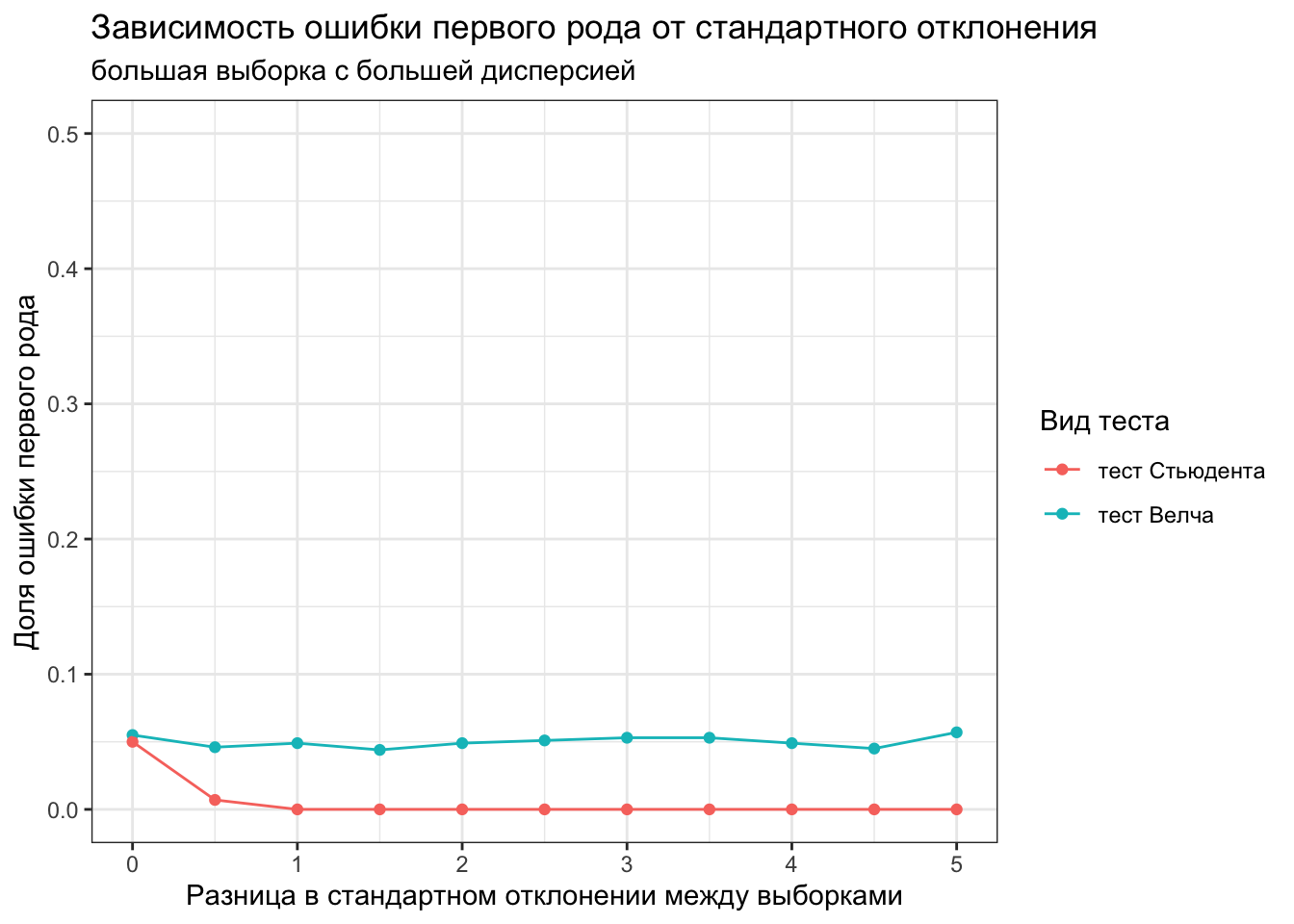
Проверим, что будет, если наоборот, большая выборка будет с большей дисперсией.
Code
var_size <-seq(0, 5, 0.5)calculate_mean_error_1st_type <-function(x, var.equal) {mean(replicate(1000, t.test(rnorm(1000, 0.2, 1), rnorm(9000, 0.2, 1+x), var.equal = var.equal)$p.value) <0.05)}welch_error_1st_type <-map_dbl(var_size, ~calculate_mean_error_1st_type(., FALSE))students_error_1st_type <-map_dbl(var_size, ~calculate_mean_error_1st_type(., TRUE))data.frame(var_size, welch_error_1st_type, students_error_1st_type) %>%pivot_longer(cols =c(welch_error_1st_type, students_error_1st_type), names_to ='type', values_to ='error_1st_type') %>%ggplot(aes(var_size, error_1st_type))+geom_point(aes(color = type))+geom_line(aes(color = type))+scale_x_continuous(name ='Разница в стандартном отклонении между выборками')+scale_color_discrete(name ='Вид теста', labels =c('тест Стьюдента', 'тест Велча'))+scale_y_continuous(name ='Доля ошибки первого рода', limits =c(0, 0.5))+ggtitle('Зависимость ошибки первого рода от стандартного отклонения', subtitle ='большая выборка с большей дисперсией')+theme_bw()
Здесь тест Стьюдента работает даже лучше, доля ложноположительных результатов очень низкая. Но и тест Велча работает нормально, сохраняя ее на уровне примерно 0.05.
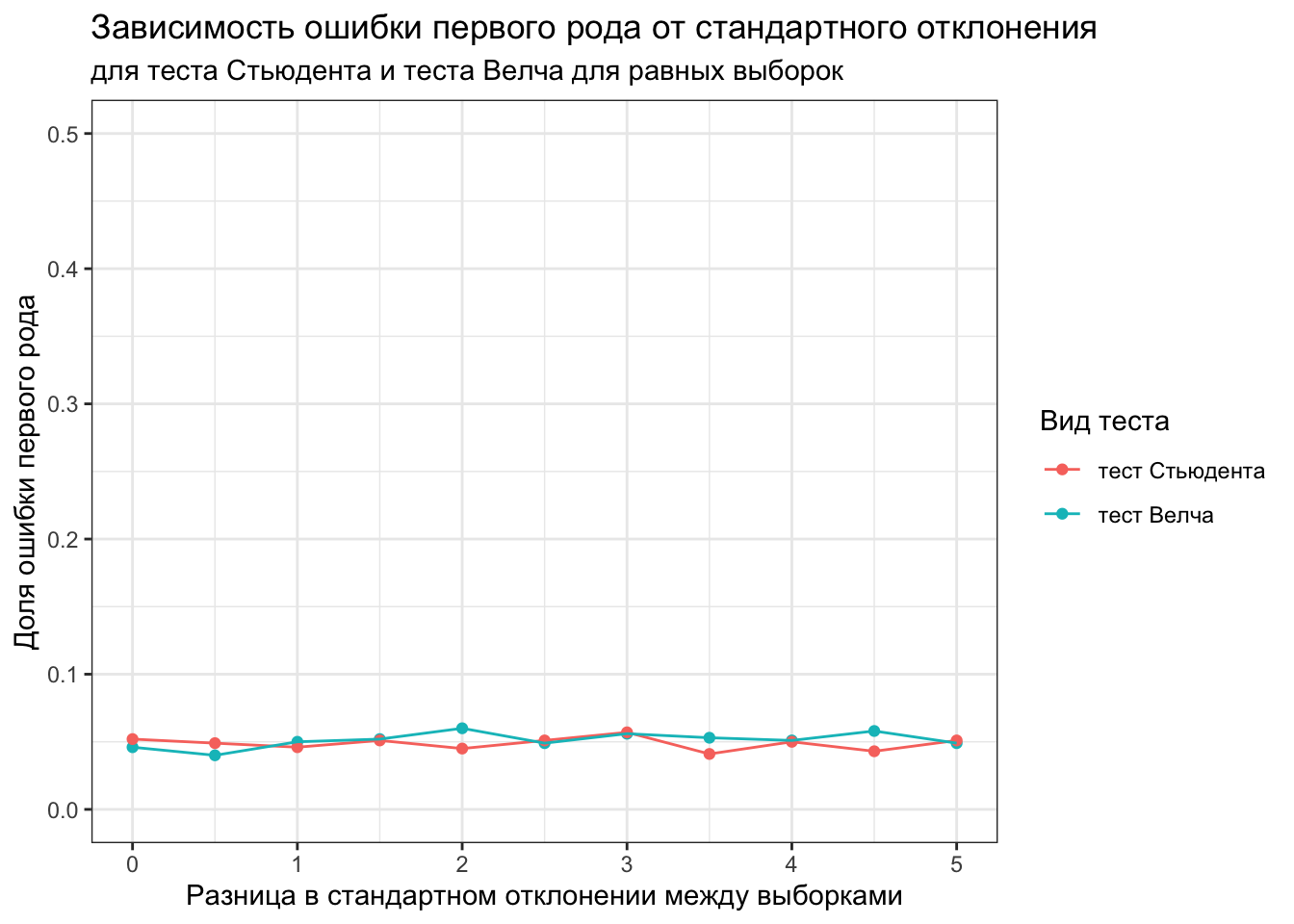
При этом при равных размерах выборок, разница в дисперсиях не влияет на оба теста.
Code
var_size <-seq(0, 5, 0.5)calculate_mean_error_1st_type <-function(x, var.equal) {mean(replicate(1000, t.test(rnorm(1000, 0.2, 1), rnorm(1000, 0.2, 1+x), var.equal = var.equal)$p.value) <0.05)}welch_error_1st_type <-map_dbl(var_size, ~calculate_mean_error_1st_type(., FALSE))students_error_1st_type <-map_dbl(var_size, ~calculate_mean_error_1st_type(., TRUE))data.frame(var_size, welch_error_1st_type, students_error_1st_type) %>%pivot_longer(cols =c(welch_error_1st_type, students_error_1st_type), names_to ='type', values_to ='error_1st_type') %>%ggplot(aes(var_size, error_1st_type))+geom_point(aes(color = type))+geom_line(aes(color = type))+scale_x_continuous(name ='Разница в стандартном отклонении между выборками')+scale_color_discrete(name ='Вид теста', labels =c('тест Стьюдента', 'тест Велча'))+scale_y_continuous(name ='Доля ошибки первого рода', limits =c(0, 0.5))+ggtitle('Зависимость ошибки первого рода от стандартного отклонения', subtitle ='для теста Стьюдента и теста Велча для равных выборок')+theme_bw()
Таким образом, при одинаковом размере выборок, тест Стьюдента устойчив к нарушению предположения о равенстве дисперсий. Однако, в ситуации, когда выборки разного размера, причем большая выборка с меньшей дисперсией, тест Стьюдента начинает завышать ошибку первого рода.
Поэтому наиболее надежно будет использовать тест Велча в любом случае, вне зависимости от равенства дисперсий и размера выборок, так как он сохраняет ошибку первого рода на заданном уровне \(\alpha\) .
NoteОффтоп
Кстати, и у теста Манна-Уитни не все хорошо в таком примере
Оба теста нашли отличия там, где они есть в 100% случаев, что говорит о высокой мощности тестов, даже если отличия не очень большие (тут размер выборки примерно как в A/B тестировании, в биологии выборки будут поменьше).
Попробуем добавить неравенство дисперсий.
Разное среднее, разная дисперсия, равный размер выборок
Среднее отличается, и еще стандартное отклонение в одной из выборок выше на 2.
Оба теста показали хороший результат в этом случае, возможно даже тест Стьюдента немного лучше.
Выводы
В большинстве случаев оба теста контролируют ошибку первого рода и мощность на заданном уровне. Однако у теста Стьюдента есть проблема с ошибкой первого рода (ложноположительные результаты) в ситуации с неравными дисперсиями и разным размером выборок.
Здесь ✅ — тест показал себя хорошо, ❌ — тест показал себя плохо, 🟡 — тест показал себя не оптимально, но не слишком плохо
тест Велча
тест Стьюдента
Отличий нет, равные дисперсии, равные выборки
✅
✅
Отличий нет, разные дисперсии, равные выборки
✅
✅
Отличий нет, разные дисперсии, разные выборки, меньшая выборка с большей дисперсией
✅
❌
Отличий нет, разные дисперсии, разные выборки, бОльшая выборка с большей дисперсией
✅
✅
Отличия есть, равные дисперсии, равные выборки
✅
✅
Отличия есть, разные дисперсии, равные выборки
✅
✅
Отличия есть, разные дисперсии, разные выборки, меньшая выборка с большей дисперсией
🟡
✅
Отличия есть, разные дисперсии, разные выборки, бОльшая выборка с большей дисперсией
✅
🟡
Поэтому рекомендация использовать тест Велча вне зависимости от дисперсий остается актуальной.
NoteЧто можно еще изучить:
В этом материале не рассмотрела, что будет при небольших размерах выборок, проверила только часть из разобранных кейсов. В плане ошибки первого рода выводы не меняются на малых выборках, а вот для оценки мощности нужно реализовать более сильные эффекты, так как на малых выборках не хватает мощности обоих тестов.
Возможно, вынесу разбор этого в отдельный пост, так как здесь уже и так информации достаточно много.
Подписывайтесь на телеграм-канал, кто еще этого не сделал, пишите комментарии в телеграме или здесь!